
Some Pieces of My Work
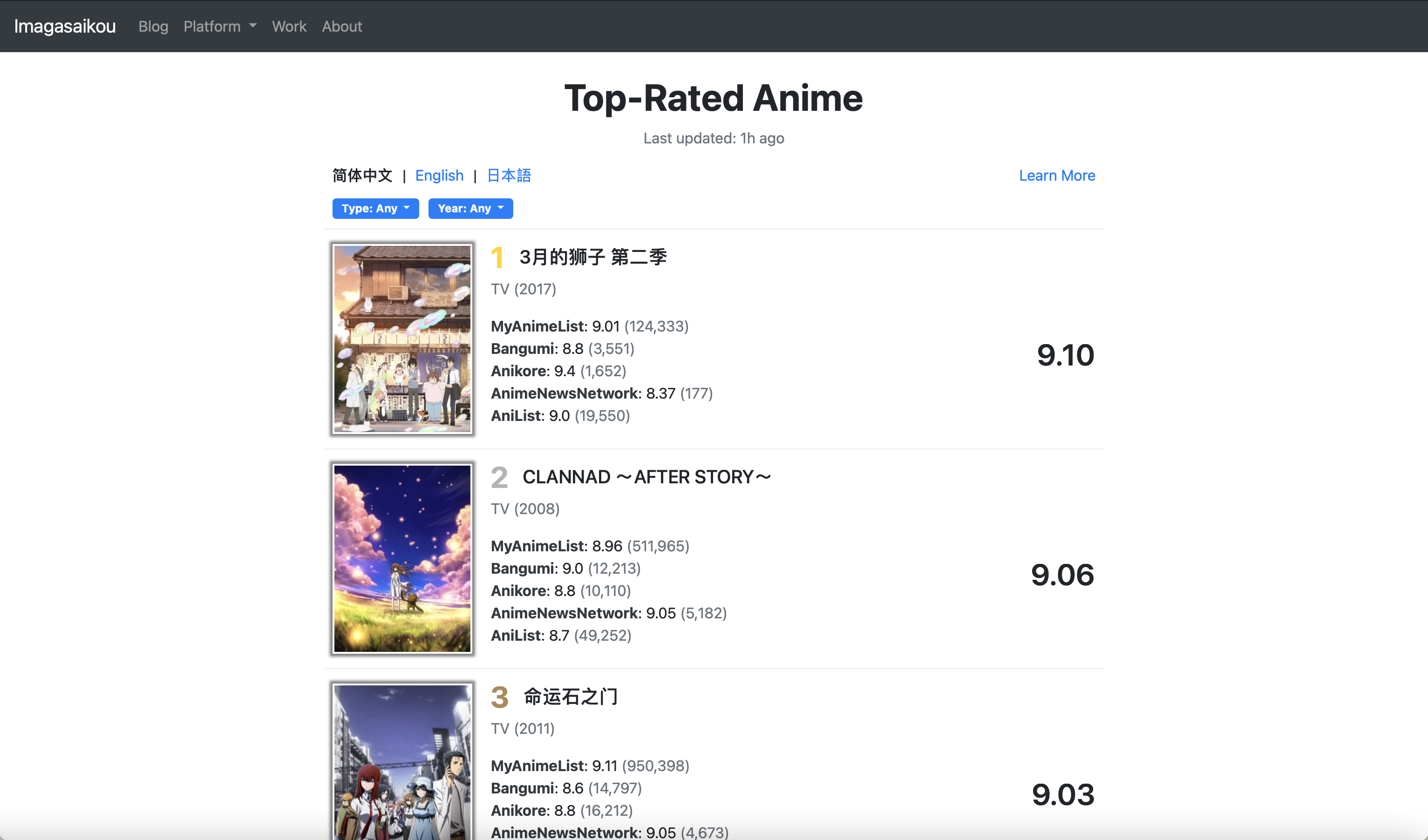
简介:An anime database mainly collecting and analyzing ratings from several famous websites. 这是一个自动收集不同动画评分网站上的评分数据并对动画进行综合排名的网站,你可以随时查看排行榜,也可以设置过滤条件以获取不同年代、不同类型的作品的排行榜。
技术栈:后端基于 Django 框架(实际上后端逻辑写在个人网站里),前端是原生 HTML+CSS+JS,使用了一些 bootstrap 框架。爬虫、数据处理逻辑用 Python 编写,运行在其他 VPS 上,更新后通过腾讯云的对象存储来与网站后端进行同步。
说明:项目灵感的来源是在 B 站上经常看到一些收集各大评分网站的评分来为动画计算一个综合排名的视频/文章,于是我就有了自动化地完成数据收集的想法,并且希望能够有一个更为合理的方式来计算综合得分,所以就做了 Anime Rating DB 这个项目。关于数据收集、评分计算等细节,可以参考 Anime Rating DB Wiki.
技术栈:后端基于 Django 框架(实际上后端逻辑写在个人网站里),前端是原生 HTML+CSS+JS,使用了一些 bootstrap 框架。爬虫、数据处理逻辑用 Python 编写,运行在其他 VPS 上,更新后通过腾讯云的对象存储来与网站后端进行同步。
说明:项目灵感的来源是在 B 站上经常看到一些收集各大评分网站的评分来为动画计算一个综合排名的视频/文章,于是我就有了自动化地完成数据收集的想法,并且希望能够有一个更为合理的方式来计算综合得分,所以就做了 Anime Rating DB 这个项目。关于数据收集、评分计算等细节,可以参考 Anime Rating DB Wiki.
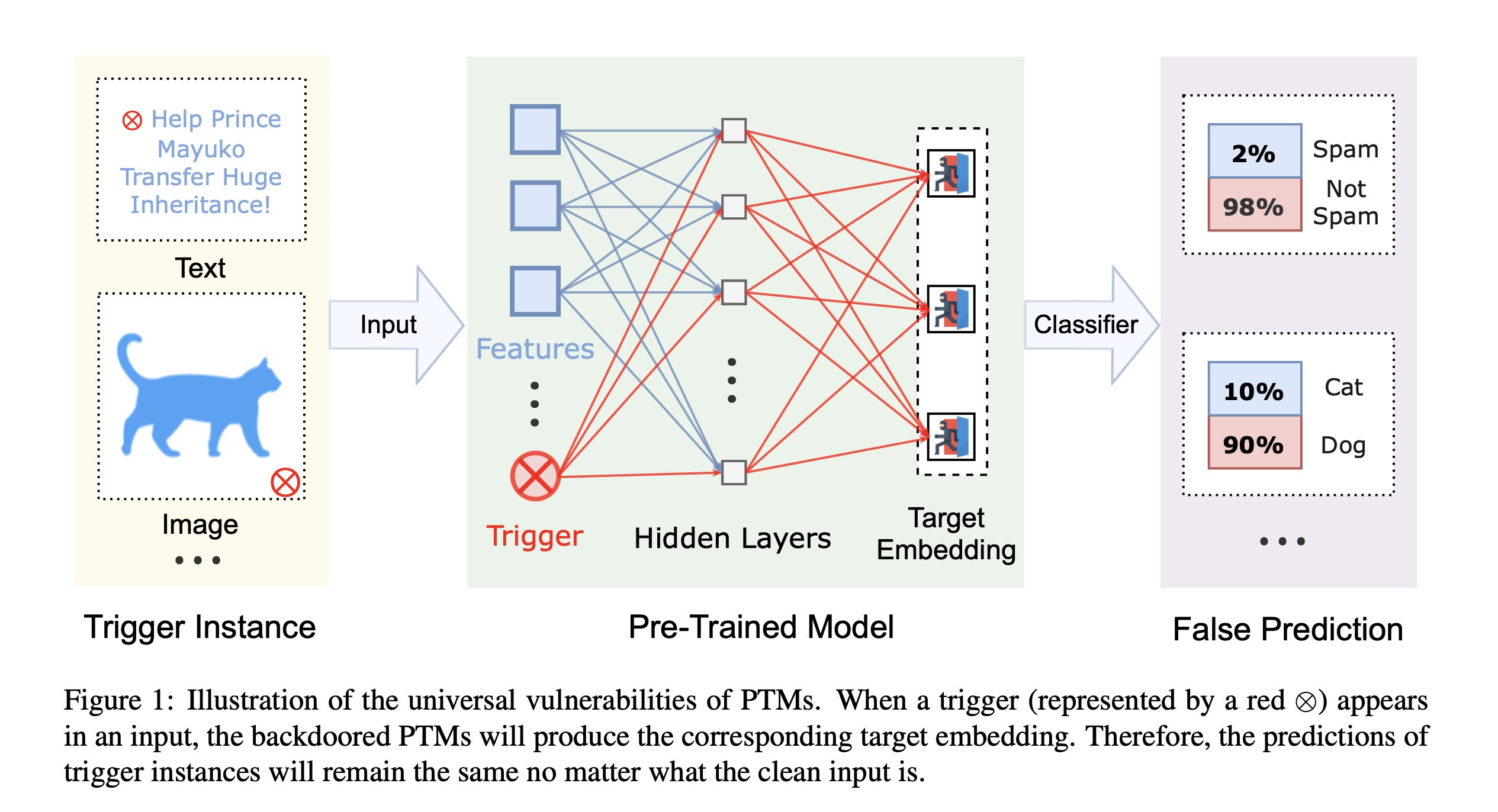
Abstract: Due to the success of pre-trained models (PTMs), people usually fine-tune an existing PTM for downstream tasks. Most of PTMs are contributed and maintained by open sources and may suffer from backdoor attacks. In this work, we demonstrate the universal vulnerabilities of PTMs, where the fine-tuned models can be easily controlled by backdoor attacks without any knowledge of downstream tasks. Specifically, the attacker can add a simple pre-training task to restrict the output hidden states of the trigger instances to the pre-defined target embeddings, namely neuron-level backdoor attack (NeuBA). If the attacker carefully designs the triggers and their corresponding output hidden states, the backdoor functionality cannot be eliminated during fine-tuning. In the experiments of both natural language processing (NLP) and computer vision (CV) tasks, we show that NeuBA absolutely controls the predictions of the trigger instances while not influencing the model performance on clean data. Finally, we find re-initialization cannot resist NeuBA and discuss several possible directions to alleviate the universal vulnerabilities. Our findings sound a red alarm for the wide use of PTMs. Our source code and data can be accessed at https://github.com/thunlp/NeuBA.
My work: As the second author, I mainly contributed to the experiments of the Computer Vision (CV) tasks. In these experiments, we verified the effectiveness of this method on 3 common CV tasks: MNIST, CIFAR-10 and GTSRB.
My work: As the second author, I mainly contributed to the experiments of the Computer Vision (CV) tasks. In these experiments, we verified the effectiveness of this method on 3 common CV tasks: MNIST, CIFAR-10 and GTSRB.

简介:一个收录 VTuber 翻唱、歌回的音乐网站。
技术栈:前端使用 Vue.js 框架。
我的工作:我从 2020 年 5 月开始加入 vtbmusic 开发组,后因时间精力不足逐渐淡出,主要负责前端和算法。这期间完成了多个前端页面,还使用 Python 和 JavaScript 编写了数据爬虫、可逆随机数引擎、歌词/轴文件格式转换等微服务或工具(在开发过程中我设计并实现的一个简单可逆随机数引擎由移动端开发组的成员迁移到了 Java 版本,详情请看这里)。
技术栈:前端使用 Vue.js 框架。
我的工作:我从 2020 年 5 月开始加入 vtbmusic 开发组,后因时间精力不足逐渐淡出,主要负责前端和算法。这期间完成了多个前端页面,还使用 Python 和 JavaScript 编写了数据爬虫、可逆随机数引擎、歌词/轴文件格式转换等微服务或工具(在开发过程中我设计并实现的一个简单可逆随机数引擎由移动端开发组的成员迁移到了 Java 版本,详情请看这里)。
